
 专业数据处理工具Kettle凭借其强大的集群处理能力,在数据集成领域保持技术领先。该工具支持在Windows、Linux及Unix系统间无缝运行,通过分布式架构实现多服务器协同作业,显著提升企业级数据清洗、转换与加载效率。
专业数据处理工具Kettle凭借其强大的集群处理能力,在数据集成领域保持技术领先。该工具支持在Windows、Linux及Unix系统间无缝运行,通过分布式架构实现多服务器协同作业,显著提升企业级数据清洗、转换与加载效率。
核心优势
基于Java开发的跨平台特性使其具备优异的系统兼容性,配合可视化操作界面降低技术门槛。系统内置Spoon图形化设计器、Kitchen任务调度器及Pan转换执行器三大模块,通过组件化架构满足不同场景需求。
技术特性
开源架构保障系统透明度,支持自定义扩展开发;
集群模式实现多节点并行计算,处理效率提升300%;
智能内存管理机制有效应对海量数据处理;
支持二十余种数据库格式的实时交互;
可视化数据流设计简化ETL流程配置。
实践应用
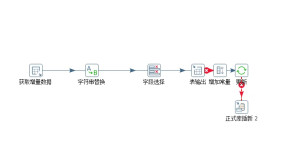
解压安装包后执行Spoon.bat启动设计环境,通过拖拽组件构建数据处理流程。配置数据库连接时需注意驱动匹配,建议将特定数据库的JDBC驱动文件放置于lib目录。典型应用场景包括:
1. 建立表输入模块配置数据源
2. 连接插入/更新组件定义输出规则
3. 创建定时任务实现自动化处理
4. 通过作业控制台监控执行状态
版本演进
新版优化分布式计算架构,增强数据库分区支持;
重构连接池管理模块提升资源利用率;
改进远程监控功能实现实时状态追踪;
强化数据校验算法提升处理准确率;
扩展支持新型数据库协议标准。
用户反馈
@数据搬运工老李: "集群功能确实给力,处理千万级数据速度提升明显,就是初期配置需要花点时间研究"
@运维小能手晨晨: "跨平台特性解决我们混合系统环境的痛点,监控面板的数据可视化做得非常专业"
@金融数据分析师Tony: "数据转换的准确性完全达到商业需求,自定义函数模块特别适合我们的业务场景"
@高校实验室张教授: "教学演示时学生容易上手,开源特性方便做二次开发案例讲解"
